فایل robots.txt موضوعی است که در این مقاله از آکادمی کاپریلا قصد داریم به آن بپردازیم. در این مقاله علاوه بر اینکه با فایل robots.txt آشنا شده، در مورد مزیتها و کاربردهای سئویی آن نیز اطلاعاتی کاملی را به دست خواهید آورد.
فایل robots.txt چیست؟
robots.txt یک فایل متنی است که به خزندهها و رباتهای موتور جستجو اعلام میکند که به کدام یک از صفحات سایت شما دسترسی داشته باشند و کدام یک را بررسی و ایندکس نکنند. در حقیقت این فایل برای اعلام صفحاتی از سایت به خزندههای گوگل است که نمیخواهیم به آن دسترسی داشته و آن را ایندکس کنند. علاوه بر گوگل، سایر موتورهای جستجو، مثل یاهو و بینگ نیز به فایل robots.txt توجه کرده و دستور عملهای آن را اجرا میکنند.
اگر میخواهید برخی از صفحات سایت شما توسط خزندههای موتورهای جستجو، ایندکس و بررسی نشود و به بیان دیگر رباتها به این صفحات دسترسی نداشته باشند، میتوانید از فایل robots.txt استفاده کنید. البته باید توجه داشته باشید برای مخفی و دور نگه داشتن صفحهای از سایت خود، نباید همیشه از فایل robots.txt استفاده کرد. یعنی توصیه میشود در چنین مواردی به جای استفاده از robots.txt از تگ noindex برای آن صفحه استفاده شود . کاربرد اصلی robots.txt برای مواقعی است که میخواهیم از لود شدن بیش از حد یک صفحه جلوگیری کنیم. در ادامه کاربرد و موارد استفاده آن را به طور دقیقتری بیان میکنیم.
آیا فایل robots.txt برای همه سایتها ضروری است؟
با اینکه فایل robots.txt کاربرد مهمی دارد، اما باید بدانید که وجود آن برای هر سایتی ضرورتی ندارد. چون گوگل معمولاً به طور خودکار صفحاتی که تکراری نیستند و یا از اهمیت زیادی برخوردار نمیباشد را تشخیص داده و ایندکس نمیکند. با این وجود سایتها به دلایل زیر به فایل robots.txt نیاز پیدا خواهند کرد:
مسدود کردن صفحات خاص
ممکن است در سایت شما صفحاتی وجود داشته باشد که نخواهید توسط گوگل ایندکس شده و مورد بررسی قرار گیرد. در چنین شرایطی میتوانید فایل robots.txt را برای سایت خود ایجاد کنید و در آن دسترسی موتورهای جستجو به صفحه یا صفحات مورد نظر خود را مسدود نمایید.
استفاده حداکثری از بودجه خزیدن رباتهای گوگل
اگر در ایندکس تمام صفحات سایت شما مشکلی وجود دارد، یکی از دلایل آن میتواند مشکل در بودجه خزیدن رباتهای گوگل باشد. در این حالت میتوانید صفحاتی که از اهمیت کمتری برخوردار است را در فایل robots.txt مسدود کنید. با این کار بودجه خزش گوگل برای سایت شما، برای صفحات بیاهمیت صرف نمیشود و به جای آن این سهم خزش، صرف ایندکس کردن صفحات مهم میگردد. این موضوع به ویژه در سایتهای پربازدید، اهمیت و تاثیر خود را بیشتر نشان میدهد.
بهترین روش ساختن فایل robots.txt چیست؟
اولین قدم برای اینکه یک فایل robots.txt برای سایت خود داشته باشید، این است که در ابتدا از طریق notepad یک فایل متنی ایجاد کنید و در آن دستور زیرا را وارد نمایید:
User-agent: *
Disallow: /images
این دستور به تمام رباتهای گوگل میگوید که تصویرهای سایت ایندکس نشود. این دستور فقط یک نمونه بود، اما این دستور به شکلهای دیگر نیز میتواند نوشته شود. این دستور را با هم بررسی و تحلیل میکنیم.
خط اول دستور یعنی عبارت :User-agent رباتهای گوگل را مشخص میکند. در این خط مشخص میکنیم که میخواهیم دسترسی کدام یک از رباتهای گوگل را به صفحات مد نظر خود مسدود نماییم. زمانی که مانند مثال بالا از ستاره * استفاده کنیم، یعنی به تمام رباتهای گوگل اعلام کردیم که به صفحات دسترسی نداشته باشند و آن را ایندکس نکنند.
در عبارت Disallow، صفحاتی از سایت را مشخص میکنیم که میخواهیم رباتهای گوگل به آن دسترسی نداشته باشد (اجازه دسترسی را مسدود میکنیم). استفاده از / به تنهایی جلوی :Disallow به معنای این است که دسترسی رباتهای گوگل را به تمام صفحات سایت مسدود کردهاید. اگر میخواهید صفحه خاصی را مسدود کنید، کافیست که جلوی /:Disallow آدرس آن صفحه را قرار دهید.
پس از نوشتن دستور، فایل robots.txt را با نام robots.txt ذخیره کرده و آن را در روت اصلی هاست خود آپلود کنید.

استفاده از robots.txt چه محدودیتهایی دارد؟
قبل از اینکه فایل robots.txt را برای سایت خود ایجاد کنید و یا اینکه آن را ویرایش نمایید، بهتر است که محدودیتهای آن را درک کرده و از آن آگاهی داشته باشید. امکان دارد که تمامی موتورهای جستجو، دستور عملهای فایل robots.txt را پشتیبانی نکنند. همچنین ممکن است که دستورالعملهای این فایل نتواند جلوی خزش صفحات را بگیرد. این موضوع به خزندههای موتورهای جستجو بستگی دارد. ممکن است که برخی از خزندهها از دستور عملهای فایل robots.txt پیروی کنند و در مقابل، ممکن است که برخی دیگر پیروی نکنند. بنابراین اگر میخواهید دسترسی به یکی از صفحات سایت خود را توسط موتورهای جستجو مسدود کنید، بهتر است که روشهای دیگری را به کار ببرید.
خزندههای و رباتهای معتبر موتورهای جستجو، فایل robots.txt در نظر گرفته و دستورالعملهای آن را رصد میکنند، اما با این حال ممکن است که هر خزنده به شکل متفاوتی دستورالعملها را تفسیر کند. همچنین ممکن است که برخی از خزندهها اصلا دستوالعملهای خاصی را درک نکنند. فرض کنید که شما دسترسی به صفحهای از سایت خود را با استفاده از robots.txt مسدود کردید، اما این صفحه از صفحات دیگر لینک دارد، در این حالت ممکن است که صفحه مسدود شما همچنان ایندکس شود.
همانطور که اشاره کردیم، گوگل محتوای صفحه مسدود شده در فایل را بررسی نمیکند. اما اگر این صفحه از سایر صفحات، لینکهایی را داشته باشد، ممکن است که گوگل آدرس را پیدا کرده و آن را همچنان ایندکس نماید. اگر میخواهید صفحهای را از دید موتورهای جستجو پنهان کنید و با اطمینان کامل دسترسی رباتهای گوگل را به آن مسدود نمایید، میتوانید روشهایی مثل تگ noindex به جای فایل robots.txt به کار ببرید.
چگونه خطاهای robots.txt را پیدا کنیم؟
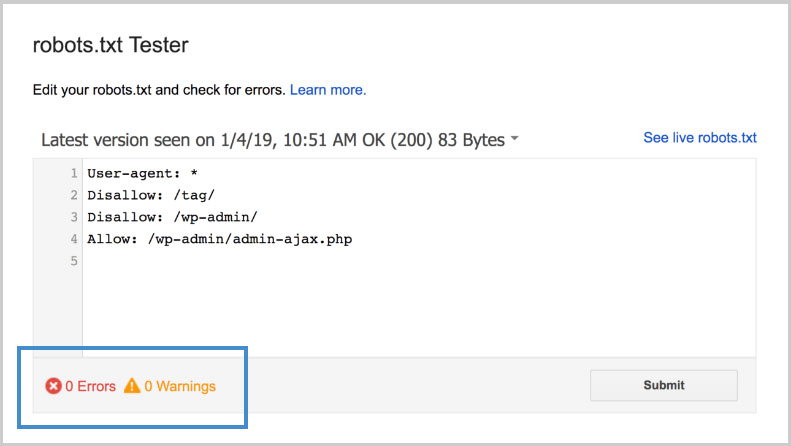
اگر استفاده از این فایل و نظارت بر آن برای شما مهم است، میتوانید برای آگاهی از خطاهای احتمالی که ممکن است در ایندکس شدن صفحات سایتتان مشکل ایجاد کند، از ابزارهای رایگان تست robots.txt استفاده کنید. یکی از بهترین و مطمئنترین گزینههای تست robots.txt، ابزار Robots Testing Tool گوگل است.
جمعبندی
فایل robots.txt موضوعی نیست که بخواهید همیشه آن را استفاده کنید و بر روی آن نظارت داشته باشید. برای مسدود کردن صفحات سایت، میتوانید از روشهای دیگری که در این مقاله به آن اشاره کردیم، نیز استفاده کنید. اما با این حال فایل نیز روشی برای مسدود کردن رباتهای گوگل به صفحات سایت است.
اگر این مطلب برای شما مفید بوده است، آموزشها و مطالب زیر نیز به شما پیشنهاد میشوند:
- آموزش سئو در وردپرس (WordPress SEO)
- آموزش تحقیق کلمات کلیدی برای سئوی سایت
- مجموعه آموزش دیجیتال مارکتینگ (Digital Marketing)
- آموزش گوگل آنالیتیکس (Google Analytics) برای تحلیل آمار وب سایت
- آموزش مبانی بازاریابی محتوا (Content Marketing)
- آموزش آنالیز و بهینه سازی سایت با GTmetrix
- آموزش کار با ابزار Google Tag Manager
- آموزش Google Data Studio برای آنالیز داده ها و گزارش دهی



